( 읽기전에 MoE(링크)논문을 읽는걸 추천드립니다. )
[ Abstract ]
최근 LLM(large-language-model)이 뛰어난 성능을 보이며, 여러 LLM을 효과적으로 활용하는 방법이 중요한 연구 주제가 되고 있다.
우리는 LLM의 집단적 강점을 활용하는 Mixture-of-Agents (MoA) 방법론을 제안한다.
MoA는 계층적 구조를 가지며, 각 계층(layer)은 여러 개의 LLM 에이전트(agent)로 이루어져 있다. 각 에이전트는 이전 계층의 모든 에이전트가 생성한 출력을 보조 정보로 활용하여 응답을 생성한다.
MoA 모델은 AlpacaEval 2.0, MT-Bench, FLASK 등의 벤치마크에서 최신 최고 성능(SOTA) 을 달성했으며, 특히 오픈소스 LLM만으로 구성된 MoA 모델이 GPT-4 Omni(57.5%)를 뛰어넘어 65.1%의 점수를 기록했다.
[ Introduction ]
LLM들이 성능이 좋아졌지만, 모델 크기 및 학습 데이터의 제약이 있으며, 각 모델마다 강점과 약점이 있다. 우리는 다수의 LLM의 집단적 전문 지식을 활용하여 강력하고 견고한 모델을 만들 수 있다.
LLM들이 다른 모델의 출력(낮은 품질의 응답이더라도)을 참고하면, 단독으로 생성할 때보다 저 좋은 답변 현상 발견 → 이에 MoA 방법론 제안
MoA는 여러 LLM agents를 계층적으로 배치 첫번 째 layer에서 입력을 각각의 agents가 독립적으로 응답 생성, 이후 layer의 각각의 agent들이 이전 층의 응답을 기반으로 일관된 답변 생성
(layer_2의 에이전트: layer_1의 모든 모델들이 생성한 답변 + 원본 질문. layer_n의 에이전트: layer_n-1의 모든 모델들이 생성한 답변 + 원본 질문.)
각 layer에 어떤 LLM을 배치할지는 (성능지표, 출력 다양성 → 두 가지를 모두 고려)을 기준으로 배치 진행

[ MoA Methodology ]
LLM들은 다른 모델의 출력을 참고할 때 더 높은 품질의 응답을 생성함, 이를 위해, LLM들을 두 가지 역할(Proposers, Aggregators)로 구분하여 활용
- Proposers: 높은 점수를 기록할 필요는 없다. 다양한 관점과 풍부한 맥락을 참조할 답변 생성(후속 단계에 유용)
- Aggregators: 여러 모델의 출력을 고품질 응답으로 합성, 낮은 품질의 입력도 효과적으로 통합
대부분 모델이 Proposers, Aggregators의 역할에 강하나 아닌 모델도 있다.
여러 Aggregator를 반복적으로 사용하여 응답을 점진적으로 개선하는 방식이 MoA설계 핵심 방법이다.
[ 계층 구조 설명 ]
i개의 층(layer)으로 구성되고 각 층은 n개의 agnets로 구성 여기서 동일한 llm이 같은 층 내에서나 다른 층에서도 재사용될 수 있다.
(만약 한 층에 동일한 llm이 여러개 일 경우{single-proposer}도 (stochasticity of temperature sampling 때문에) 다른 출력 생성 {소수의 고유한 출력만이 의미 있게 기여})

여기서 ‘+’는 텍스트의 단순 연결(concatenation)을, ‘⊕’는 Table 1에 제시된 Aggregate-and-Synthesize 프롬프트를 적용하는 과정을 의미합니다.
MoA는 MoE의 개념을 확장했다. MoE는 모델 내부에 expert를 두나, MoA는 여러 LLM을 계층적 배치진행
MoA는 모델 구조를 변경하지 않고 단순히 프롬프트 입력으로 결과를 도출하여 기존의 gating network 기능 수행, fine-tuning 없이도 계산비용 절감
[ Evaluation ]
환경 설정 : 각 모델의 응답은 GPT-4 (gpt-4-1106-preview)의 응답과 직접 비교됩니다. GPT-4 기반 평가자가 어느 응답이 더 우수한지 결정하며, 이를 통해 길이 편향을 줄이기 위해 길이 제어(LC) 승률 방식을 사용합니다.
- LC(length-controlled) : 일반적으로 모델은 긴 답변에 대해 자세하다는 인상을 줘 높은 평가를 받는 경향이 있음, 이를 통제하기 위해 길이 제한 MoA는 3개의 layer로 구성, 각 층은 동일 모델, 마지막 층 Qwen1.5-110B-chat(다른 version도 있음)
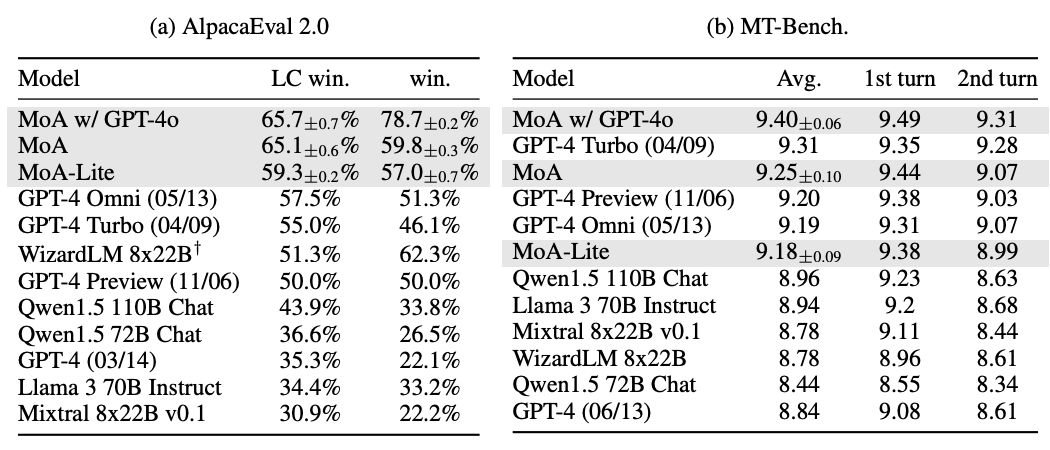
MoA는 AlpacaEval 2.0에서 GPT-4o를 8.2% 상회하며, MT-Bench에서도 sota
[ MoA 연구 ]
- MoA가 LLM기반 ranker방식(aggregator에서 통합이 아닌 단순 선택)보다 우수함
- Aggregator가 생성한 최종 답변과 개별 Proposer 답변 간의 텍스트 유사도 사이에 비례관계에 따라 MoA가 우수한 답변할 수 있음
- proposer의 수가 많아질수록 품질 향상, proposer layer안에서도 동일 모델을 사용하는 것 보다, 서로 다른 llm을 사용하는 multiple-proposer가 더 좋은 성능을 보임
- aggregator, proposer model 실험
[ 결론 ]
여러 LLM을 계측적으로 배치해, 모델 간 협업을 통해 성능을 개선하는 MoA 방법로 제시, 단일 모델에 비해 성능 향상 (AlpacaEval 2.0에서 GPT-4o를 8.2% 상회)
한계점으로 첫 토큰이 최종층에 도달하기 전까지 기다려야 하기 때문에 지연발생, 층수를 줄이는 방식등으로 해결 (중간 결과가 자연어로 표현되여 모델의 작동원리를 쉽게 이해할 수 있는 효과도 있다.) (다른 LLM의 결과를 참조 할 때 더욱 효과적인 답변 생성 → Multi Agent 시스템에 도입 해보면 좋을듯 )
'AI_Paper > NLP' 카테고리의 다른 글
| RAGAS: Automated Evaluation of Retrieval Augmented Generation 논문리뷰 (0) | 2025.02.24 |
|---|---|
| Agent-as-a-Judge: Evaluate Agents with Agents 논문 리뷰 (0) | 2025.02.21 |
| MoE(Mixtral of Experts) 논문리뷰 (0) | 2025.02.18 |
| MoE(OUTRAGEOUSLY LARGE NEURAL NETWORKS:THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER) 논문리뷰 (0) | 2025.02.18 |
| LLAMA 논문리뷰 (0) | 2024.01.15 |



